|
Hi! I am Xinyuan Cao (曹馨元), a fifth-year PhD student in Machine Learning at Georgia Institute of Technology. I am fortunate to be advised by Prof. Santosh Vempala. Before joining Gatech, I received my Master's degree in Data Science from Columbia University, supervised by Prof. John Wright. I obtained my Bachelor's degree in Mathematics at Fudan University. I have broad interest in machine learning, optimization and graph. My research mainly focuses on developing efficient and provable machine learning algorithms and building theories that inspire the machine learning practitioners! |

|
|
|
|
|
|
| Contrastive Moments: Unsupervised Halfspace Learning in Polynomial Time |
|
| Provable Lifelong Learning of Representations |
|
|
|
|
* indicates equal contribution. |
|
|
|
|
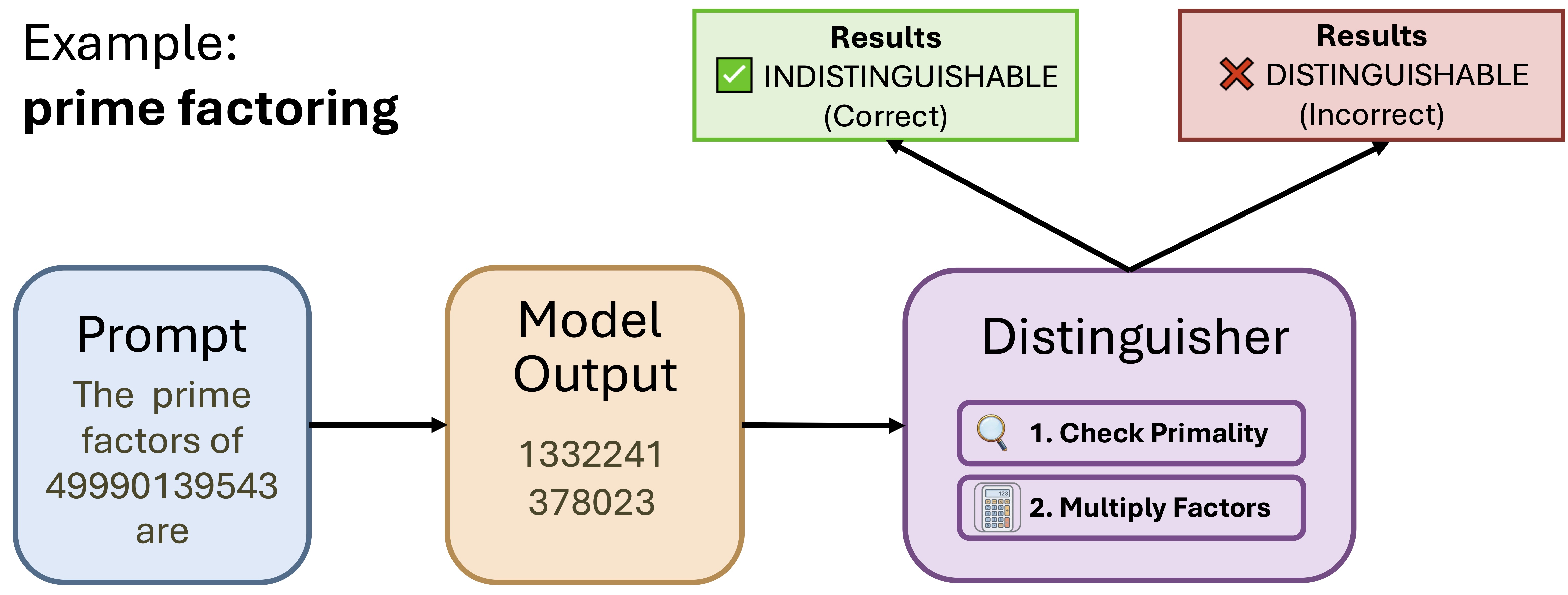
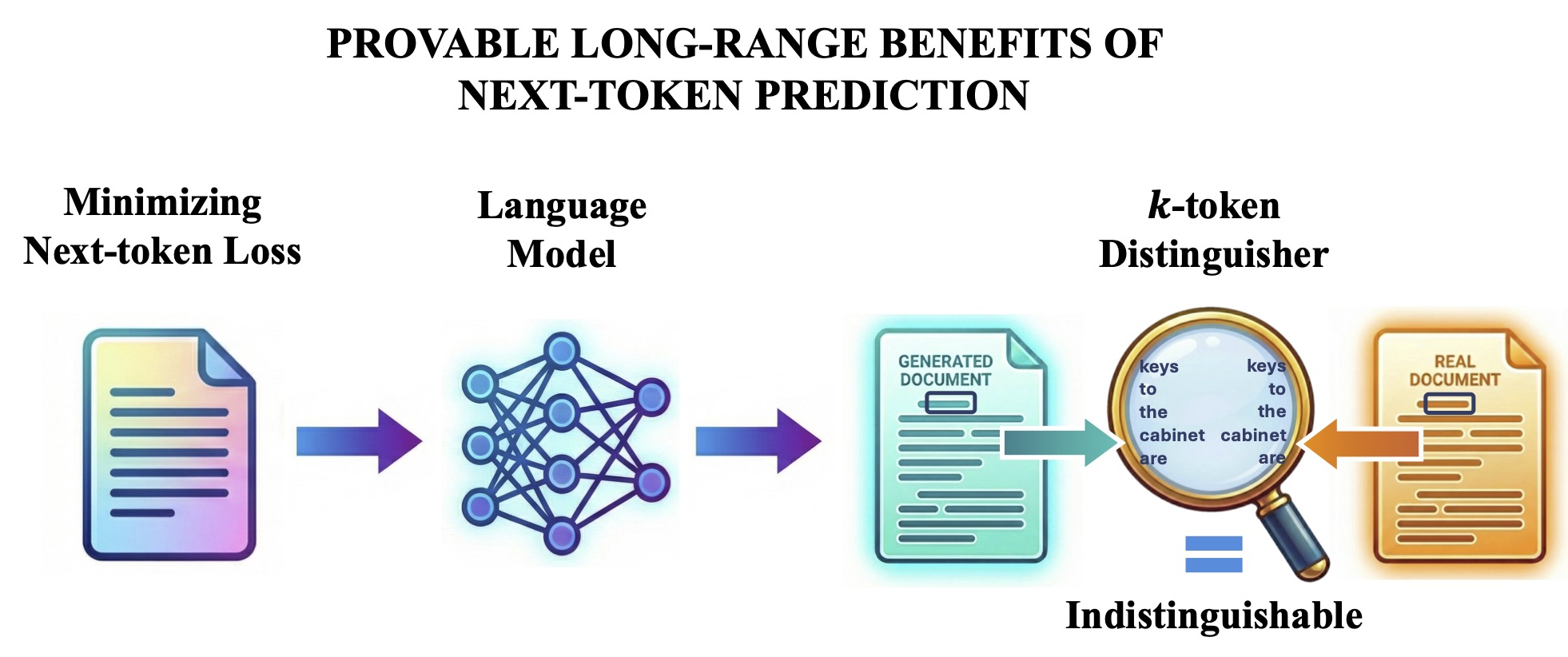
Xinyuan Cao, Santosh Vempala STOC 2026 Why do modern language models, trained to do well on next-word prediction, appear to generate coherent documents and capture long-range structure? Here, we prove that standard next-token training yields a model that is k-token indistinguishable from training data, even for arbitrarily long generations. |
|
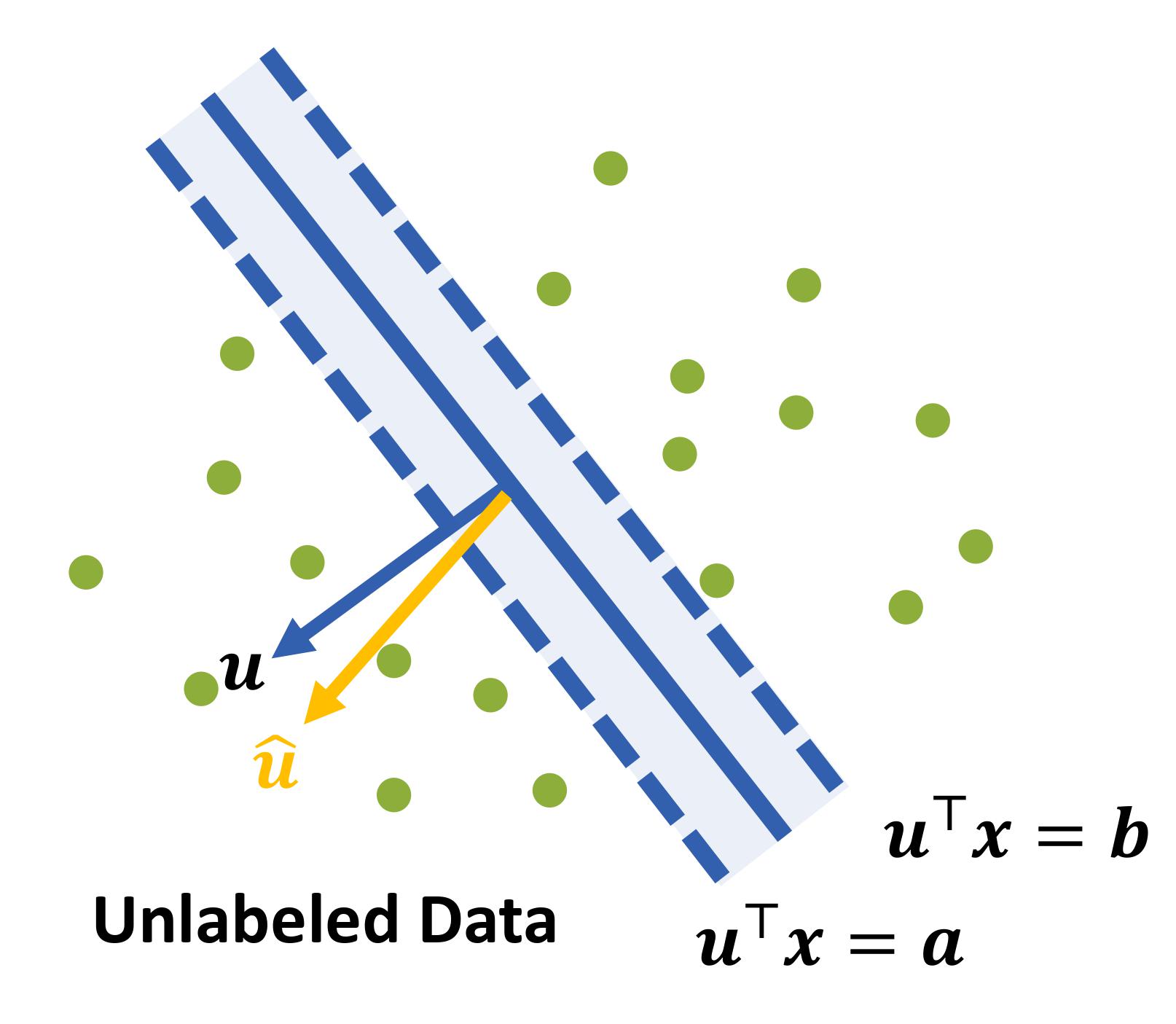
Xinyuan Cao, Santosh Vempala NeurIPS 2023 We propose a provable and efficient unsupervised learning algorithm to learn the max margin classifier with linearly separable unlabeled data through a contrastive approach. The approach uses re-weighted first and second moments to compute the direction of the max margin classifier. |
 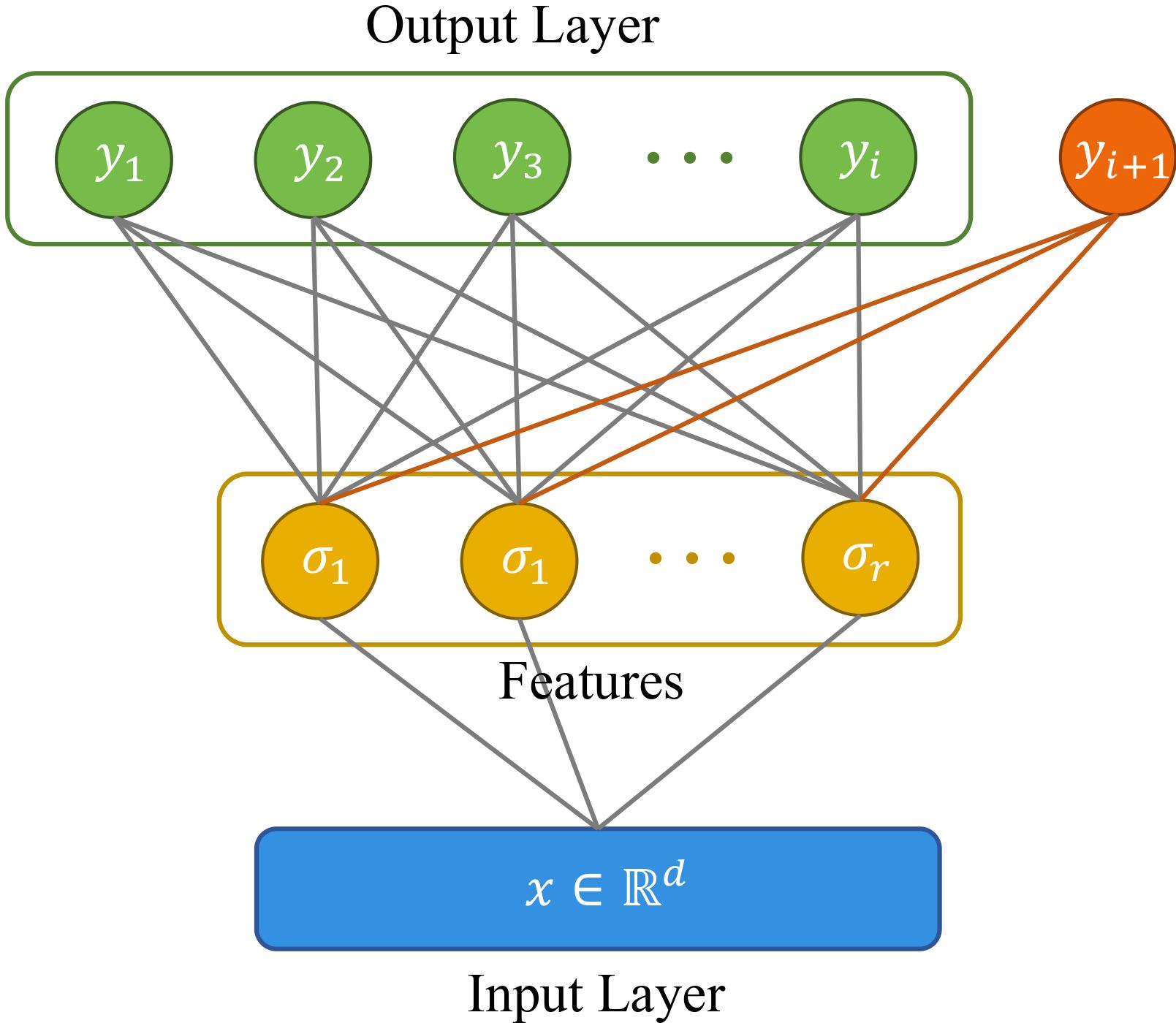
|
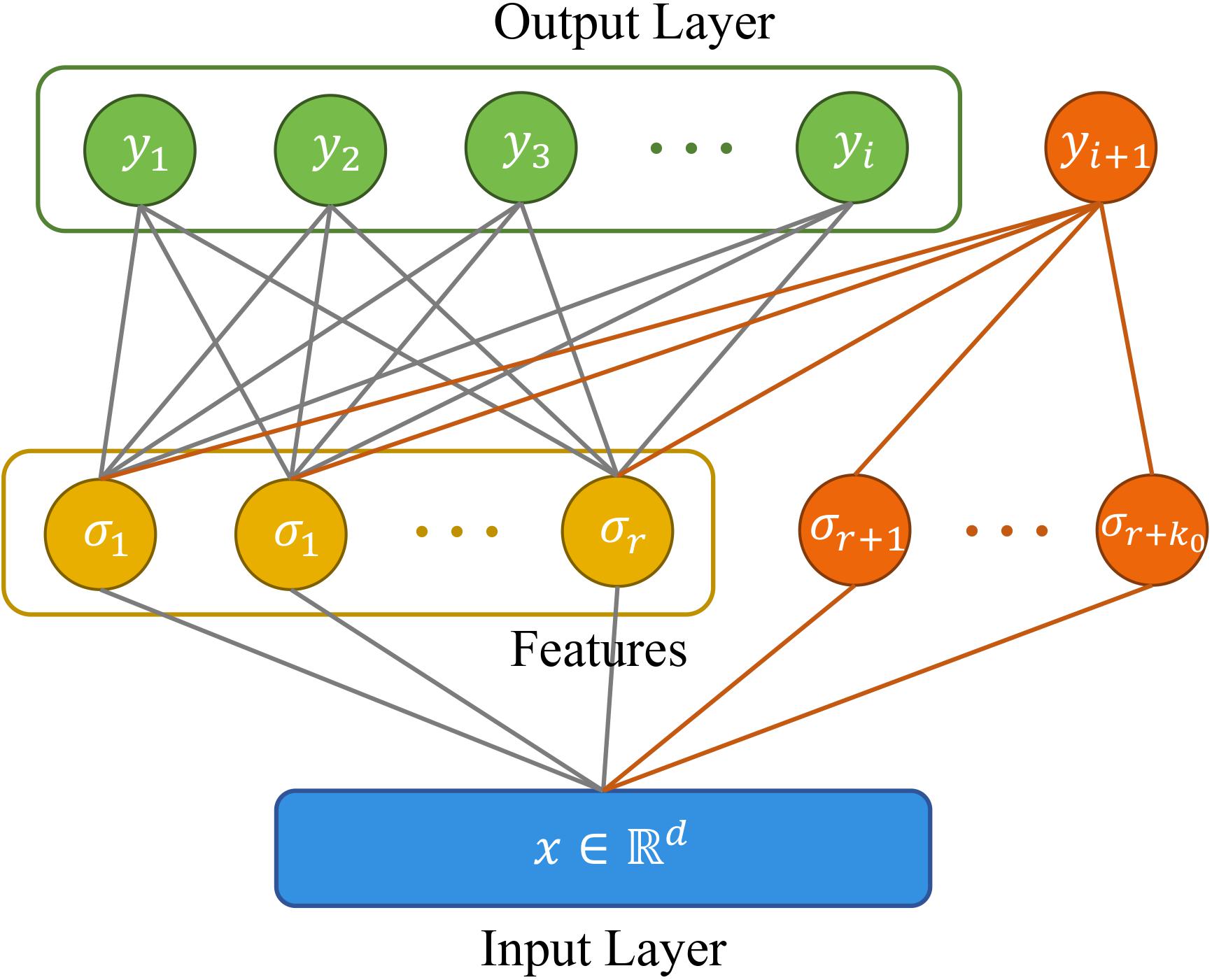
Xinyuan Cao, Weiyang Liu, Santosh Vempala AISTATS 2022 We propose a lifelong learning algorithm that maintains and refines the internal feature representation and prove nearly matching upper and lower bounds on the total sample complexity. We also complement our analysis with an empirical study, where our method performs favorably on challenging realistic image datasets compared to state-of-the-art continual learning methods. |
|
|
|
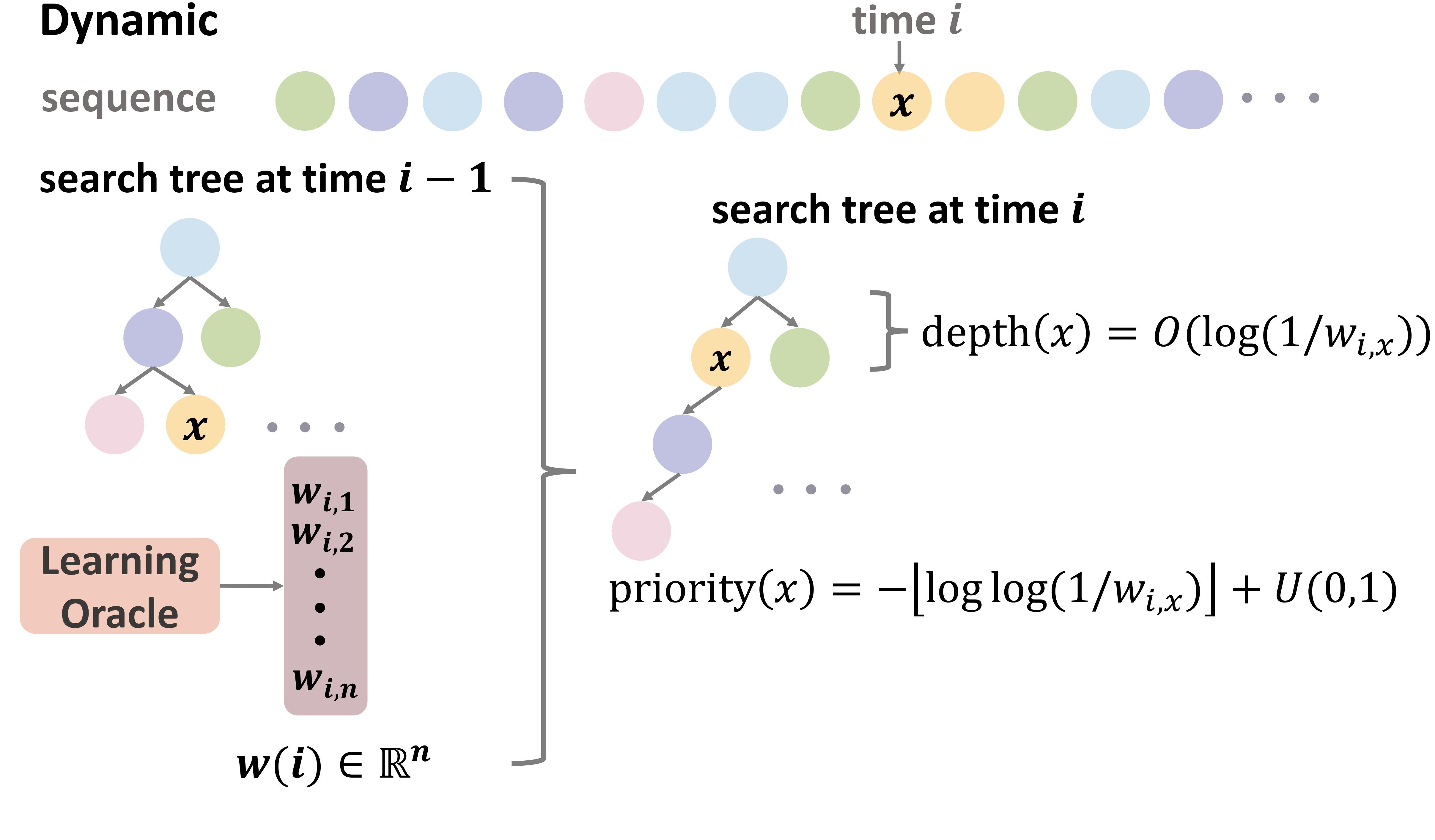 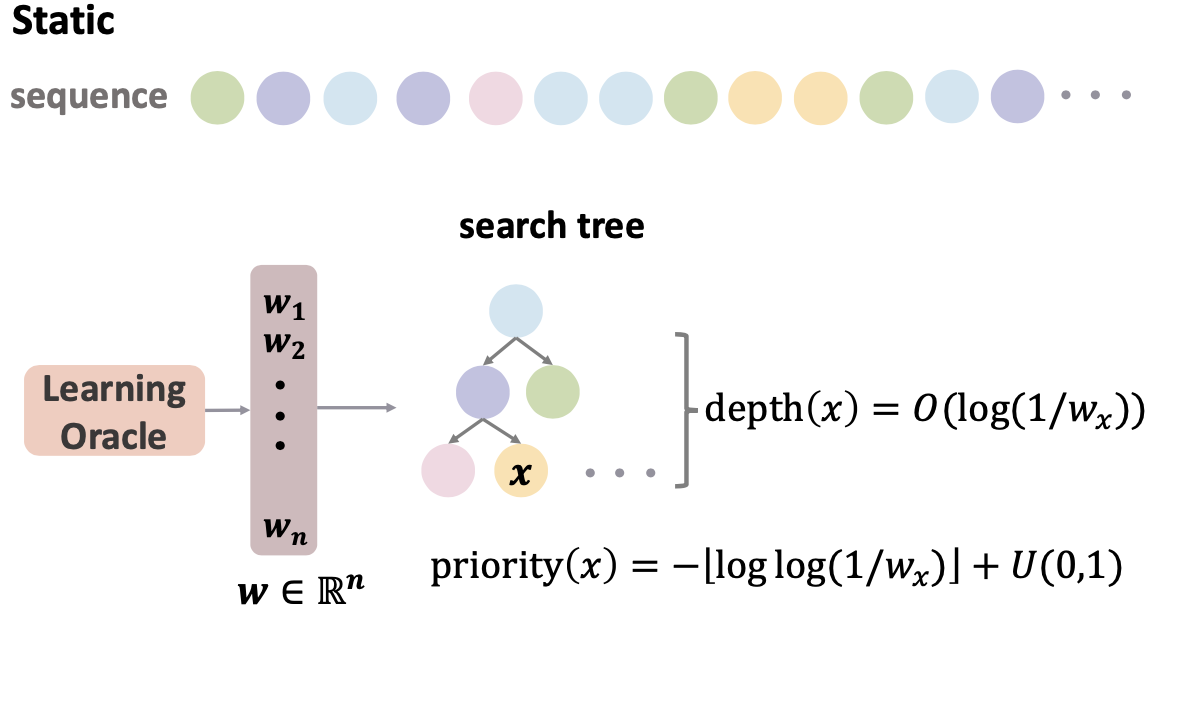
|
Jingbang Chen*, Xinyuan Cao*, Alicia Stepin, Li Chen ICML 2025 We study learning-augmented binary search trees (BSTs) and B-Trees via Treaps with composite priorities. It also gives the first B-Tree data structure that can provably take advantage of localities in the access sequence via online self-reorganization. The data structure is robust to prediction errors and handles insertions, deletions, as well as prediction updates. |
|
|
|
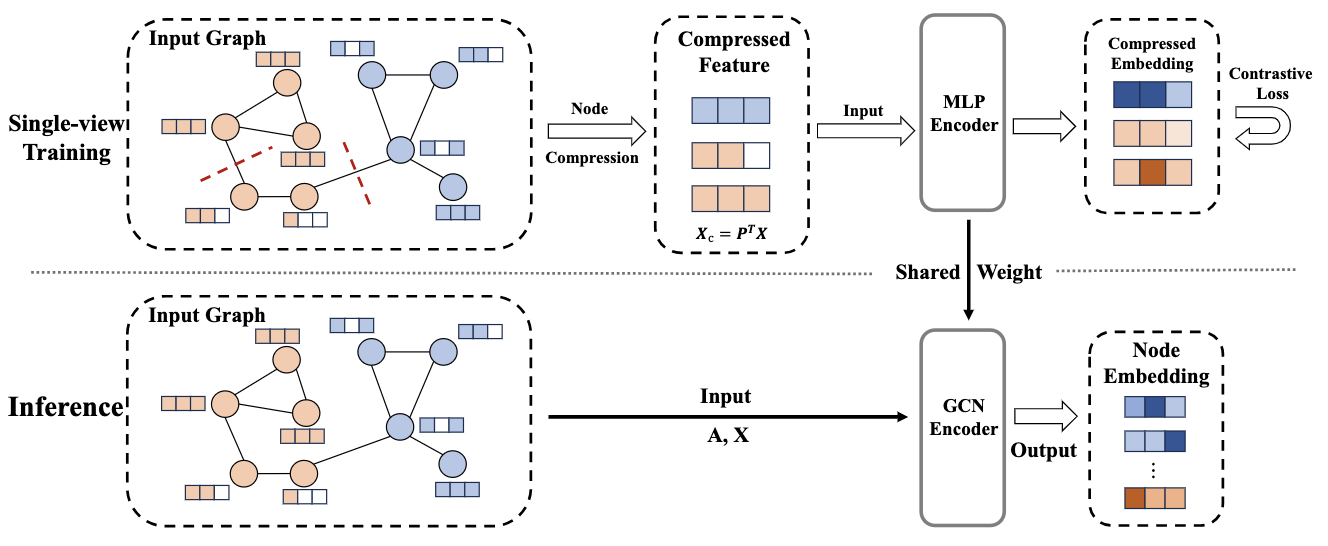
|
Shengzhong Zhang, Wenjie Yang, Xinyuan Cao, Hongwei Zhang, Zengfeng Huang ICLR 2024 We propose a simple yet effective training framework called Structural Compression (StructComp) to do graph contrastive learning. Inspired by a sparse low-rank approximation on the diffusion matrix, StructComp trains the encoder with the compressed nodes. This allows the encoder not to perform any message passing during the training stage, and significantly reduces the number of sample pairs in the contrastive loss. |
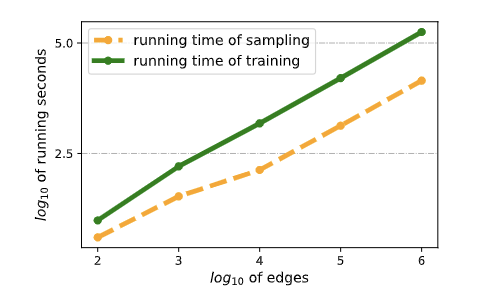
|
Lili Wang, Chenghan Huang, Weicheng Ma, Xinyuan Cao, Soroush Vosoughi WWW 2023 We present a novel method for temporal graph-level embedding that involves constructing a multilayer graph and using a modified random walk with temporal backtracking to generate temporal contexts for the graph’s nodes. |
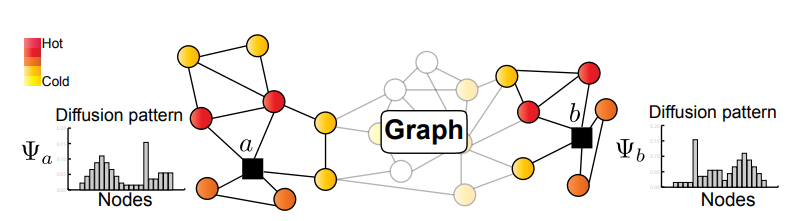
|
Lili Wang, Chenghan Huang, Weicheng Ma, Xinyuan Cao, Soroush Vosoughi CIKM 2021 We propose a novel unsupervised whole graph embedding method. Our method uses spectral graph wavelets to capture topological similarities on each k-hop sub-graph between nodes and uses them to learn embeddings for the whole graph. |
|
|
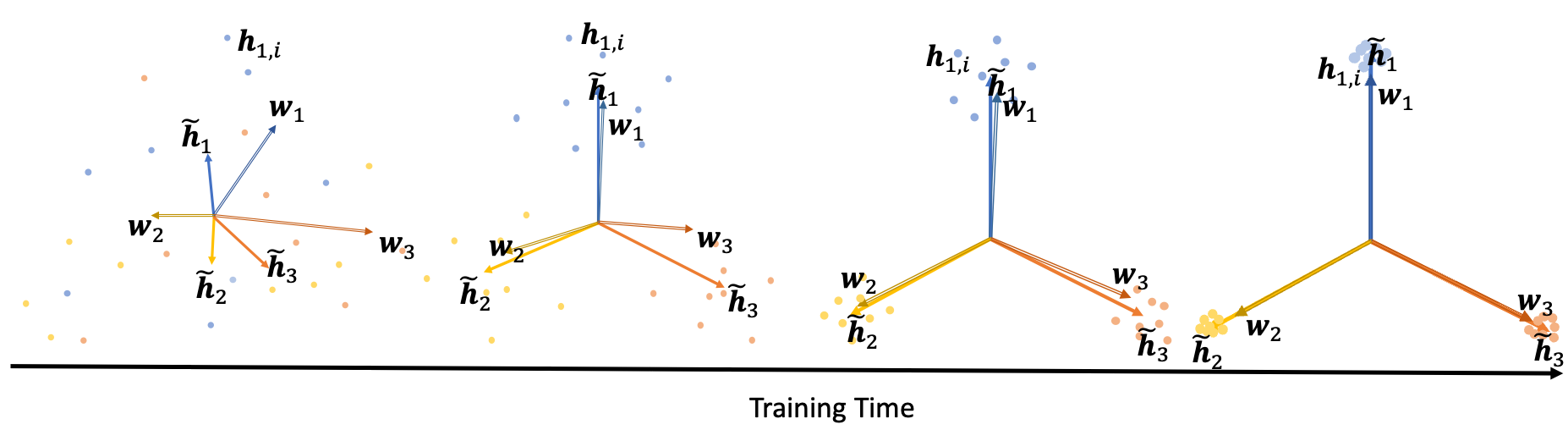
|
Leyan Pan, Xinyuan Cao We investigate the interrelationships between batch normalization (BN), weight decay, and proximity to the Neural Collapse (NC) structure. Experimental evidence substantiates our theoretical findings, revealing a pronounced occurrence of NC in models incorporating BN and appropriate weight-decay values. |